Did you know that you can navigate the posts by swiping left and right?
Capstone Project Part 1 - Data Gathering
21 Jun 2018
. category:
Update
.
Comments
#UWDS
#Capstone
#Brewers Association
#TwitterAPI
#Data Gathering
Yes, Yes, I realize that I have laxed on my promise to regularly update on my capstone project and I apologize for that. Some of you may know that I have actualy completed this project and have graduated from the UWDS program, to those of you out there that this is news to, you can now consider yourself informed! ![]()
So now that I actualy have some spare time again I will hopfully start filling this blog up with content! To start I will attempt to deliver on my promise earlier this year in sharing the work done in my capstone project. I’m not sure yet but I think this will be a 4 or 5 part series describing the major aspects of the project. To the select few I asked to help edit my final paper, two things: first, thank you so much for the help! And second, this blog will look a lot like a regergitation of what you have already read. ![]()
I will do my best to get the entire series out in the next couple of months. This first update will focus on pulling data from Twitter, I hope you enjoy it (and maybe learn somthing new!) it’s a little long winded, but as always feel free to ask question in the comment section below!
(Re-)Introduction
If you recall from my innitial post my entire capstone project revolves around the Twitter accounts for The Brewers Association (BA). The group actualy has three seperate accounts all targeting diffrent customers of BA you can see the handles and there description in the following table. Based on the descriptions of the handles we can start to understand the three audiences that BA is targeting. The @BrewersAssoc and @HomebrewAssoc handles are obviously targeting the members of the two organizations that are a part of BA. It makes sense to target them separately although they are both interested in the similar topic because more often than not laws governing members of both institutions are quite different at both the state and national level. The third, @craftbeerdotcom, is another example of BA market-ing directly to their customers’ customer. This handle is quite successful with over 56,000 followers and 10,000 tweets.
| Twitter Handle | Description | |
|---|---|---|
| @BrewersAssoc | Brewers Association is the not-for-profit trade assoc. dedicated to small & independent American brewers, their beers & the community of brewing enthusiasts. | |
| @HomebrewAssoc | The American Homebrewers Association (AHA) is committed to promoting the community of homebrewers & empowering homebrewers to make the best beers in the world. | |
| @craftbeerdotcom | Bringing the stories of America’s small & independent craft brewers to life for beer lovers. Created by the Brewers Associa-tion. |
Data Gathering
This phase of the project consists of gathering data from the Twitter API via the Python package Tweepy and parsing the information returned into relational columnar datasets. In the simplest of terms, this phase reaches out to Twitter and gathers roughly 3,500 of most recent tweets sent by each of BA’s three Twitter handles.
Twitter API
To be able to gather this data one must first understand what the Twitter API is, and what can be done with it. Specifically, there are three main requests for the API including; get, post, and streaming requests. For this project, we are only concerned with get requests. For a complete understanding, I recommend reading the API documents for the other two request types. But in brief, the following is a quick description, post requests allow developers to add, edit or delete the various artifacts that are a part of a user’s profile or tweets, and the streaming requests allows for a constant and real-time stream of various tweets base on criteria. Both of these calls are often used by developers to create third-party applications (Twitter, Inc., 2018).
Get requests allow developers to access the Twitter backend similar to that of a standard database. We can send queries based on specific criteria and expect back data in a somewhat timely manner.
Rate Limits
I say a somewhat timely manner because Twitter is a large social media platform. Their servers cannot become inundated with egregious requests from developers around the world attempting to extract their data as they must have the ability to function normally for its regular users. In an attempt to combat this Twitter has developed rate limits to its various get requests. Twitter does provide this API as a free service at a cost of the use of their servers, so it is understandable that these limits are in place. They do have a paid option for the API which includes higher limits, but in an attempt to keep this project free and open for others to use, all data collected was done so using the free tier.
The rate limits for get requests at the free tier are dependent on the resource family type (which will be described in the next section) the data queried falls into. Overall the API works within fifteen-minute windows, this means any rates imposed will only be en-forced within this window. After the fifteen minutes are up the request counter starts back at zero (Twitter, 2018).
What are Resource Families?
Resource families define the different types of data that will be returned within the get request, there are twelve different resource families, although for this project we are only interested in three including users, statuses, and followers. In the table below we can see a subset of the information returned for each of these families. For the most part, one can assume that rate limits are imposed based on the resource family type although a more accurate statement would be that it is based the on the individual request type (Twitter, 2018).
| Resource Family | Relevant Data Returned |
|---|---|
| Users | Name Screen Name (Handel) Followers Count |
| Statuses | Id Text Entities (hashtags, URLs, user mentions, etc.) Retweet Count Favorite Count |
| Followers | List of users type including all followers of a queried user |
There are roughly 50 different get request types that you can use and again for this project we are only interested in a limited set, which can be found in again in the table below. Included in this table are the returned resource family, a description of the request, and the associated number of requests allowed per 15-minute window.
| Request | Resource Family | Description | Request/Window |
|---|---|---|---|
| GET statuses/user_timeline | Statuses | Returns the most recent statuses posted from the user specified. | 900 |
| GET statuses/retweets/:id | Statuses | Returns the retweets of the given tweet. | 75 |
| GET followers/list | Followers | Returns a user’s followers or-dered in which they were added. | 15 |
Introduction to Tweepy
Tweepy is an open source python package developed to easy the interaction and use of the Twitter API within Python. The package simplifies request calls to a more standard Python notation while allowing the returned data to be alterable within other packages. Below is an example of a standard URL based get request for the most recent tweets by @BrewersAssoc along with a corresponding Tweepy based request (Roesslein, 2009). (What can I say… I’m a data guy, I like tables…)
| URL based request | Tweepy equivalent | |
| https://api.twitter.com/1.1/statuses/user_timeline.json?screen_name=BrewersAssoc&count=2 | API.user_timeline(screen_name="BrewersAssoc") |
To be able to use Tweepy (or in essence any form of the Twitter API) you must first create an endpoint to the API where OAuth-based authorization can be procured, this can be done fairly simply by visiting https://apps.twitter.com/. Once done, you can then use the four tokens provided (consumer key, consumer secret, access token, and access token secret) to start querying the API. Data that is returned will be in JavaScript Object Notation or JSON format. Luckily when using Tweepy, Python automatically identifies this as a dictionary which is a built-in type (Twitter, Inc., 2018).
Data Request and Manipulations
Now that we have a way to query the necessary data for the rest of the project, we can start doing so. The basis of this project revolves around the tweets that BA has authored, luckily this is a fairly simple request to the system, as the user timeline method shown in the Tweepy Equivalent section of the table above is the exact call needed to pull one of the three handles we are interested in. In addition, the user timeline method is one of the least re-strictive requests within the API which makes pulling 3,500 tweets happen in less than 5 minutes.
Introduction to Pandas
Once the original data requests are pulled another high powered Python package can be used to help with the various preprocessing that are needed to get the data in a usable format. This package is called Pandas. As with Tweepy, Pandas is an open source package that provides high-performance, easy-to-use data structures, and data analysis tools within Python (McKinney, 2017). This package has great built-in functions that will allow us to read in the dictionaries returned from the API and create relational data tables (in CSV format) to work off of for other phases in the project.
(I know this is long winded, thanks for bearing with me, we are almost done!)
For the most part, Pandas does well with the downloaded data from the API, we have the ability to create a CSV file where each row represents an individual tweet. Most of the information that is required for this project is easily accessible within the rows, but sadly there are some additional data hiding within some of the columns of this data. In the screenshot below we can see that there are complex data types within the entities column of this table, it includes information related to hashtags, URLs, user mentions and more, all of which are important to the rest of this project.
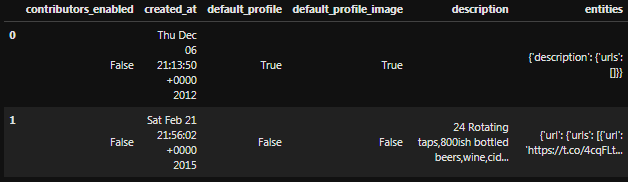
Creating Sub-tables
Fortunately, there is an easy fix to this problem, Python is able to identify this sub table structure as a dictionary with this we can create additional supporting tables to represent this data. Specifically, we can break this entities column out to four separate tables that are of use for this project including URLs, Media, Hashtags, and User Mentions and drop the rest. The relations of these tables are many-to-one to the original Tweets table and can be seen on the entity relationship diagram or ERD in below.
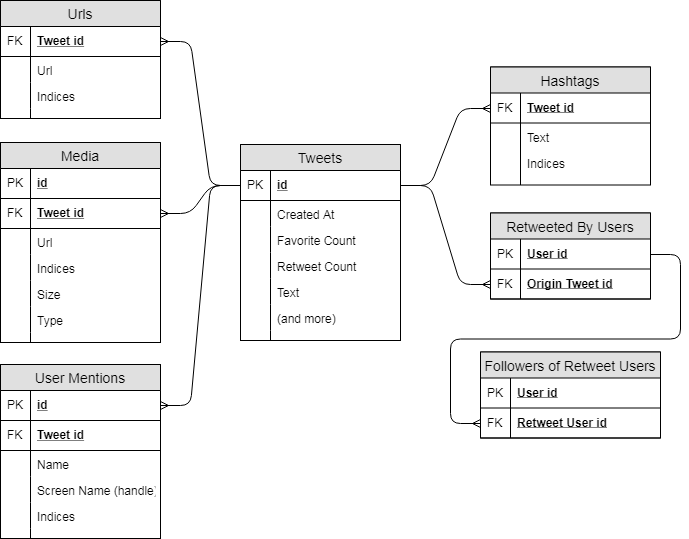
For the majority of this project (including the historical analysis, and the tagging recommendation engine (to be discussed in a later blog post)) these data tables will be all that we need. That leaves us with needing to gather data for just one additional phase of the project and that is the brand advocate investigation phase (again to be discussed in more detail at a later time).
Additional Data for Brand Advocate Investigation
This phase of the project will look into the interconnectedness between users that retweet BA tweets. Again information into the ins and outs of the thought process and analysis will be described in depth in a later blog post, for now, we will simply describe the process of procuring the additional data necessary.
In order to see interconnectedness between users that retweet, we must first be able to identify who retweeted. Again Tweepy and the Twitter API has a built-in function to do just this. As you many recall in an earlier table, there is a get request (GET status-es/retweets/:id) that returns the retweets of the given tweet. Obviously just knowing who retweeted will not be enough for this analysis, in addition, we must gather all users that are followers of those who retweeted, to do so we can use the final get request in the same table, GET followers/list. This will give us of a list of a user’s followers ordered in which they were added. These two requests will be running for only a small subset of the data as these requests, and more specifically the followers request, are regulated by Twitter at a more extreme rate.
The data subset that will be investigated will be discussed in more depth later along with a hypothesis to why the Twitter API imposes higher limits to these request types. The additional data gathered for the brand advocate investigation phase can also be seen within the ERD above as the tables Retweeted By Users and Followers of Retweet Users.
We Made It!
Thats it for this first installment, In the Next blog post I will discuss the basic historical analysis performed on the data gathered in this phase. This analysis will serve as a starting point for BA and anyone else interested in there data to be able to start to understand their historical successes (or lack there of if you are like me ![]() ) in social media.
) in social media.
Thanks agian for reading, feel free to ask me anything below!

Spencer Swartz is a Data Scientist that reciently moved to Nashville. When he's not playing around with data, he's probably trying out a new craft beer, or hanging with his wife Samantha and dog, Finn!